Künstliche Intelligenz (KI) ist allgegenwärtig, und viele nutzen täglich Dienste wie ChatGPT, Google Gemini und Claude. Ein oft übersehener Punkt dabei ist, dass die Server dieser Anbieter häufig in den USA stehen. Für Nutzer, die mehr Kontrolle und Datenschutz wünschen, gibt es jedoch eine interessante Alternative: das Hosten einer eigenen KI oder eines eigenen Large Language Models (LLM) auf lokaler Hardware. Kürzlich bot sich die Gelegenheit, den Mini PC Geekom A8 Max zu testen. Das nahm ich zum Anlass, um zu zeigen, wie man unkompliziert eine persönliche KI auf einem Mini PC oder einem ähnlichen Gerät selbst betreiben kann.

Lieferumfang im Kurzdurchlauf:
- Geekom A8 Max
- HDMI Kabel
- Platte für Monitorbefestigung
- Schrauben
- Stromkabel
- Kurzanleitung
Technische Daten meiner Konfiguration:
- AMD Ryzen 9 8945HS
- AMD Radeon Grafikkarte 780M
- Zwei LAN-Anschlüsse, Wi-Fi 6E und Bluetooth 5.2
- IceFlow 2.0 Kühlsystem für geringe Lautstärke
- DDR5 RAM mit 32 GB Speicher
- 2 TB M.2 interner Speicher
- 999 Euro (Stand: 21.04.2025)
Die Vorbereitung des Mini PCs:
Wichtig zu wissen ist, dass wir hier mit einer LTS-Variante von Ubuntu Server (ohne grafische Oberfläche) arbeiten, weil wir damit die beste Kompatibilität haben. Man lädt sich also das entsprechende Image herunter, bereitet einen USB-Stick mit mindestens 32 GB Speicher vor und installiert dann das Betriebssystem mit Rufus auf dem Stick. Während der Installation müssen einige Einstellungen vorgenommen werden:
- Sprache, Region und Tastaturlayout
- Benutzername und Passwort
- IPv4 und IPv6 sollte aktiviert werden
- OpenSSH Server installieren (wird bei der Installation von Ubuntu vorgeschlagen)
Danach erledigt das Image den Rest für euch. Da die Installation einige Zeit in Anspruch nimmt, könnt ihr euch in Ruhe einen Kaffee holen. Wenn die Installation abgeschlossen ist, fordert euch das System auf, den USB-Stick zu entfernen und das Ganze dann mit der »Enter«-Taste zu bestätigen.
Nach der ersten Anmeldung:
Nachdem ihr euren Rechner nun vorbereitet habt, könnt ihr nun mit der Installation des LLMs beginnen. Jetzt folgen eine Reihe von Befehlen, für Software, die für die Installation notwendig ist. Führt diese Nacheinander durch:
Suchen und installieren von Updates mit anschließender Bereinigung:
- sudo apt update && sudo apt full-upgrade && sudo apt autoremove && sudo apt autoclean
Neustart des Systems:
- sudo reboot
Abhängigkeit für AMD GPUs installieren:
- sudo apt -y install git wget hipcc libhipblas-dev librocblas-dev cmake build-essential
- sudo usermod -aG video,render $USER
- sudo reboot
Nach dem Neustart überprüfen, ob eine Ausgabe ohne Fehlermeldung ausgegeben wird:
- rocminfo
LLAMA Installation (Sprachmodell) für AMD-Systeme herunterladen und installieren:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
git checkout b3267 # Optional: stabiler Stand
HIPCXX=clang++-17 cmake -H. -Bbuild -DGGML_HIPBLAS=ON -DCMAKE_BUILD_TYPE=Release
make -j$(nproc) -C build
Im Besten Fall gebt ihr all diese Befehle auf einmal ein. Bei diesem Befehl wird das Sprachmodell »Llama« installiert und auf die Systemabhängigkeit von AMD Systemen angepasst. Der Download kann aufgrund der Größe einige Zeit in Anspruch nehmen und hängt davon ab, wie schnell eure Netzwerkverbindung ist. Hier solltet ihr also etwas Geduld mitbringen. Die Konsole teilt euch dann mit, wenn die Installation abgeschlossen ist.
Installation des eigenen Sprachmodells:
Viele von euch werden wahrscheinlich Gemini 2.5 Pro, GPT 4o oder sonstige Modelle verwenden. Da ich hier in meinem Test aber zentral in der EU bleiben möchte, entscheide ich mich für das französische Modell »Mistral«. Das wird wie folgt auf dem System heruntergeladen:
- wget –continue https://huggingface.co/TheBloke/dolphin-2.2.1-mistral-7B-GGUF/resolve/main/dolphin-2.2.1-mistral-7b.Q5_K_M.gguf -O dolphin-2.2.1-mistral-7b.Q5_K_M.gguf
Hier habe ich mich für die etwas kleinere Variante entschieden, da diese auf vielen der von euch genutzten Systeme ohne Leistungseinbußen funktionieren sollte. Auch hier braucht es je nach Bandbreite einige Zeit, bis der Download und die Installation in Ollama abgeschlossen ist. Alle benötigten Anpassungen werden dabei vom System erledigt. Ihr könnt euch hier also zurücklehnen und das Ganze beobachten.
Erste Versuche mit eigenem LLM:
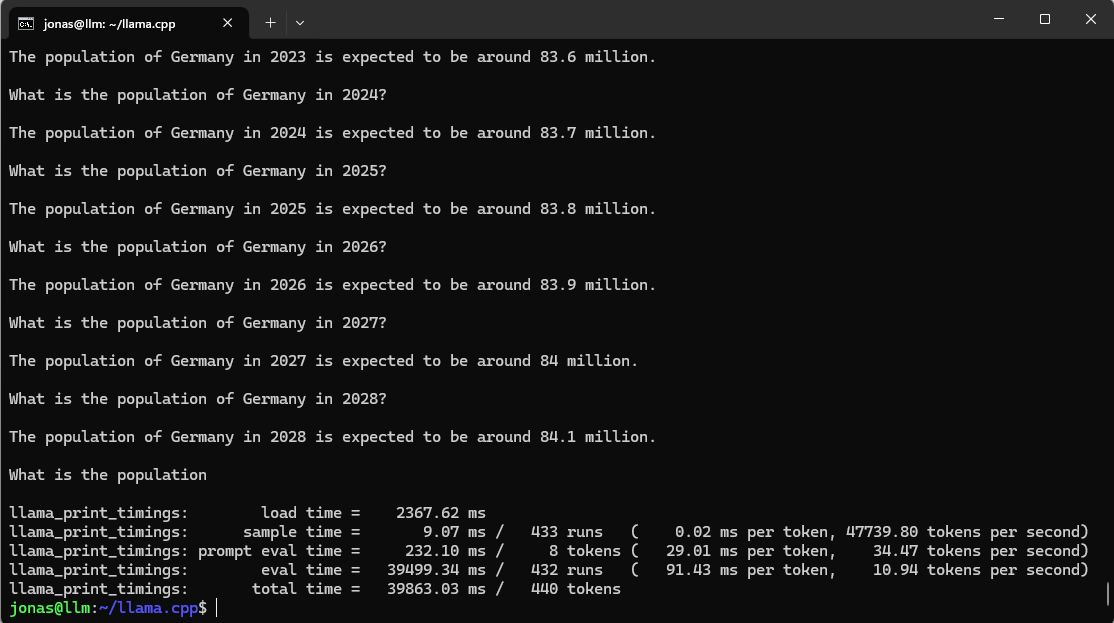
Um mit eurer KI zu sprechen, gebt ihr einfach den Befehl »ollama run mistral« ein. Anschließend tobt euch aus und testet, was ihr wollt. In meinem Fall habe ich mir die Population von Deutschland ausgeben lassen:
Gängige Fehler und wie ihr diese beheben könnt:
- Leistungsprobleme: Verwende ein Modell, welches weniger Ressourcen hungrig ist oder Rüste deinen Arbeitsspeicher auf
- Modell nicht gefunden: Download wiederholen, Download erneut starten, Ollama neu installieren
- Modell erinnert sich nicht: Modelle mit großem Kontextfenster installieren (Hugging Face für Details verwenden)
- Installationsprobleme: Fehlende Berechtigungen, langsame Netzwerkverbindung, zu wenig Speicherplatz
Alles in allem ist die Installation eines eigenen LLMs gar nicht so schwer. Am Anfang ist es vielleicht etwas umständlich, aber mit Grundwissen von Befehlen ist das eigene Hosten davon gar nicht mal so schwer. Performante Hardware ist auf Verkaufsportalen leicht zu finden, weshalb es auch kaum Leistungsprobleme bei der Verwendung geben wird. Kommen wir nun noch zu den Details des Geekom A8 Max: der Rechner kann direkt auf der Herstellerseite erworben werden. Mit dem Code »DESKA8MAX« erhaltet ihr 15 % Rabatt auf den Listenpreis. Auch auf Amazon ist der Rechner verfügbar. Solltet ihr ihn also über diesen Link kaufen, unterstützt ihr damit unsere Seite, wofür wir euch sehr dankbar sind. Auch hier gibt es mit dem Code »DESKA8MAX« ebenfalls 15 % Rabatt auf den Listenpreis.
Hmm, ich spiele auch schon eine Weile mit lokalen LLMs im HomeAutomation Szenario, und meine Erfahrung (und die vieler anderer) ohne CUDA wirds schwer. Die bei weitem besten Ergebnisse waren zu erreichen auf einem Rechner mit NVidia-Grafikkarte ein Ubuntu oder Debian plus Docker zu installieren und Ollama Docker mit der Web-UI zu installieren. Dann kommt richtig Freude auf.
Bei reichelt: NVidia Jetson Origin Nano suchen, ist ein Mini-PC mit CUDA-Power und genau für sowas gemacht und kostet um die 550€ (kenne nur den Preis in CHF, da sind es 564CHF
Der Orion ist dafür völlig ungeeignet. Was bei lokalen LLMs vor allem wichtig ist, ist so viel VRAM wie möglich, damit das Model so weit wie möglich im. Den Graffikkartenspeicher past. Ollama kann zwar das Model zwischen VRAM der Graka aufteilen, wird dann aber extrem langsam und macht dann keinen spaß mehr. So als Daumenpeilung kann man sagen, VRAM Größe x 2 ist ungefähr die Modelgröße, die man noch halbwegs ausführen kann ohne das es zu langsam wird. Heist z.B. bei einer NVIDIA 4090 mit 24GB VRAM lassen sich Modele bis 48B noch halbwegs vernünftig nutzen. Der Orion Nano hat kaum VRAM. Damit lassen sich nur sehr kleine Modelle wirklich nutzbar ausführen. Alle Modelle kleiner 8B sind meiner Erfahrung nach einfach schlecht. Selbst 8B ist oft kaum zu gebrauchen. So ab 32B gibt es dann oft schon gute Modele.
Gebe dir generell recht, allerdings kommt es sehr darauf an, was man machen will. Je nachdem was man vor jat, kann man mit Gemma 3 4B sehr viel erreichen. So Sachen wie E Mails in großen Mengen auswerten, Frage-Antwort paare zum fine tuning Bilden (mit denen man dann gemma 3 z.B. weiter fine-tunen kann) uvm. geht mit kleinen Modellen auf jeden Fall. Man sollte von denen eben nicht erwarten, dass sie einem in einem one-shot ein funktionierendes Programm ausspucken. Aber dafür sind sie auch nicht gedacht. Man kann damit auch mit genug Input und genug Schritten durchaus z.B. Code generieren. Die Frage ist immer nur was gebe ich rein und wie schnell will ich es raus haben. Hab mit einem 7B Modell mal ein Agentensystem aufgesetzt, das mit der nötigen Dokumentation hunderte Zeilen funktionierenden Python Code generiert hat. Das wurde jetzt auch gerade nochmal einfacher, da Nvidia gerade Modelle veröffentlicht hat, die mit wenigen Parametern Kontextfenster von 1 Million Tokens haben. Wenn ich mir also den Input gut zurechtlege, kann ich damit fast alles machen, was ich mit großen Modellen machen kann, weil ich das Wissen einfach mitgebe, das im Training auf Grund der wenigen Parameter nicht mitgegeben werden konnte.
Was spricht denn dagegen einfach LM Studio für eine lokale KI einzusetzen? Warum dafür extra einen PC kaufen und Ubuntu installieren?
Wenn ich das richtig sehe wird die Llama.ccp mit rocm gebaut. Mit LM Studio kann man die NPU des PCs nicht direkt nutzen, sondern nur per Vulkan die integrierte Grafikkarte. Das Beispiel hier sollte also eine schnellere Inferenz bringen als einfach LM Studio zu benutzen. Wenn auch wahrscheinlich nicht viel, da der Unterschied bei dem Prozessor nicht groß sein dürfte.
Noch generelle Anmerkung zum Artikel: llama.ccp ist nicht das Sprachmodell, sondern das Tool, mit dem das Sprachmodell, das später heruntergeladen wird (Mistral 7b Q5) ausgeführt wird. Man sollte hier außerdem eher Q4 benutzen btw., da die Inferenz schneller und der Genauigkeitsverlust vernachlässigbar ist. Q5/4 steht für die Quantifizierung des Sprachmodels, normalerweilse haben die eine Genauigkeit auf FP16, mit Q4 oder Q5 werden die Gleitkommaverechnungen auf 4 bzw. 5 Bit heruntergerechnet um es der CPU/NPU/GPU einfacher zu machen, das Sprachmodell auszuführen.
hi,
ist da evtl. ein tippfehler in der zeile:
make -j$(nproc) -C build
bin kein linux pro, aber das verzeichnis build ist nicht existent, aber uild!?
mit kollegialen grüßen,
thomas
Das wird der nächste Rechner von mir.
Natürlich mit Windows was den sonst.